

Details
Description
Petals is a decentralized platform that enables users to run large language models collaboratively. By loading a small part of the model and working together with others who serve other parts, users can run inference or fine-tuning on these models. It offers faster inference times, with single-batch inference running at approximately 1 second per step, which is up to 10 times faster than offloading. This speed makes it suitable for interactive applications like chatbots. Additionally, Petals provides more flexibility compared to traditional language model APIs. Users can employ various fine-tuning and sampling methods, execute custom paths, or access hidden states within the model. It combines the convenience of an API with the flexibility of PyTorch. The tool is currently in development and interested users can join the waitlist to try it out.
Link
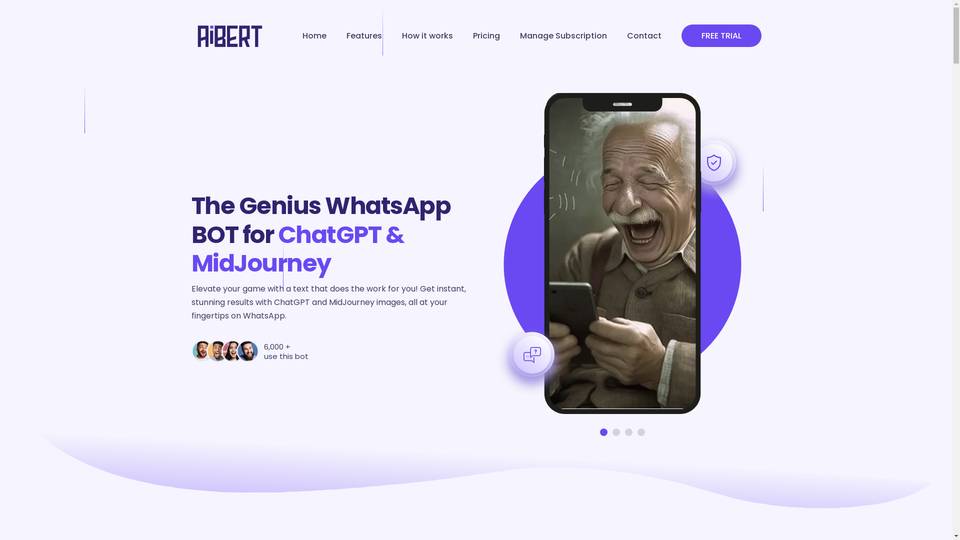
-
An impressive WhatsApp bot that provides instant responses and visually appealing images.
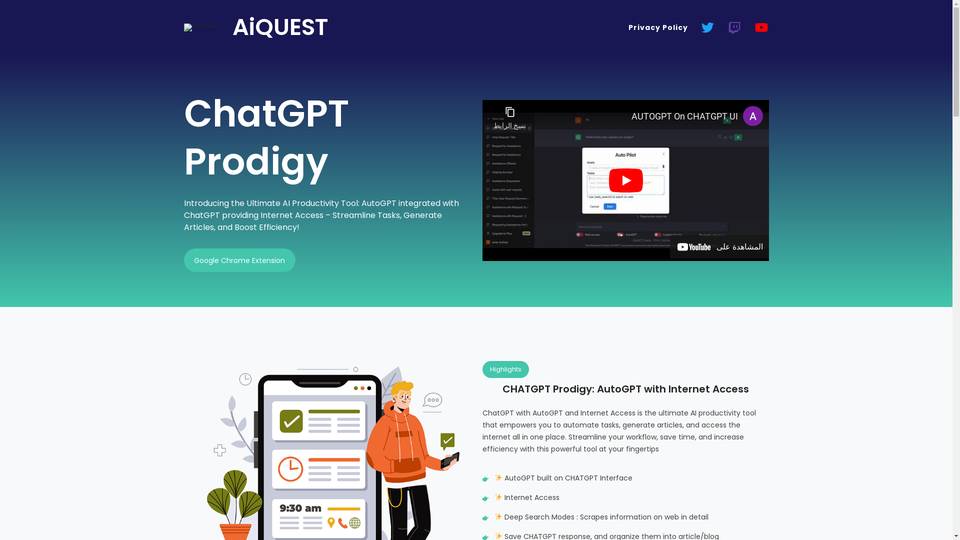
-
ChatGPT Prodigy: AI-powered productivity and research tool with internet access.
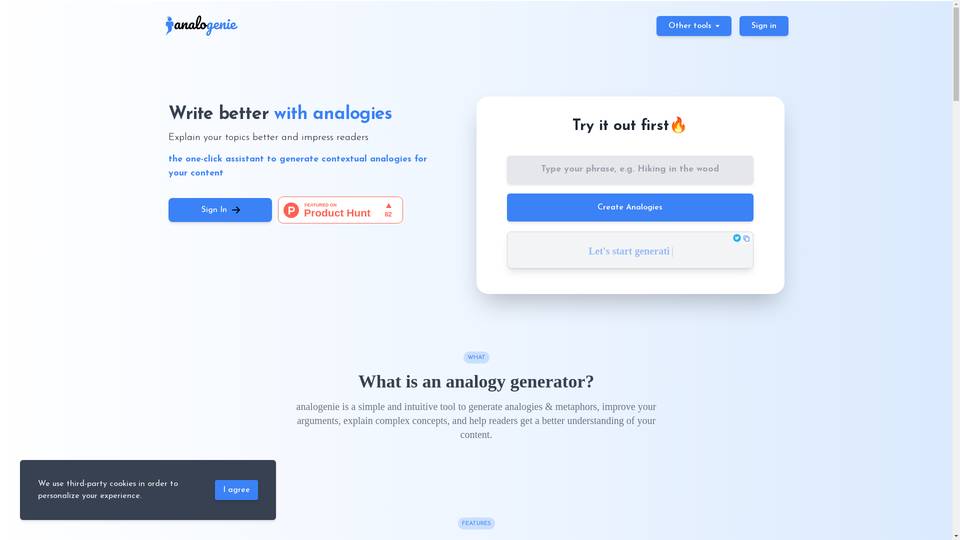
-
AI tool for generating contextual analogies to enhance written content.
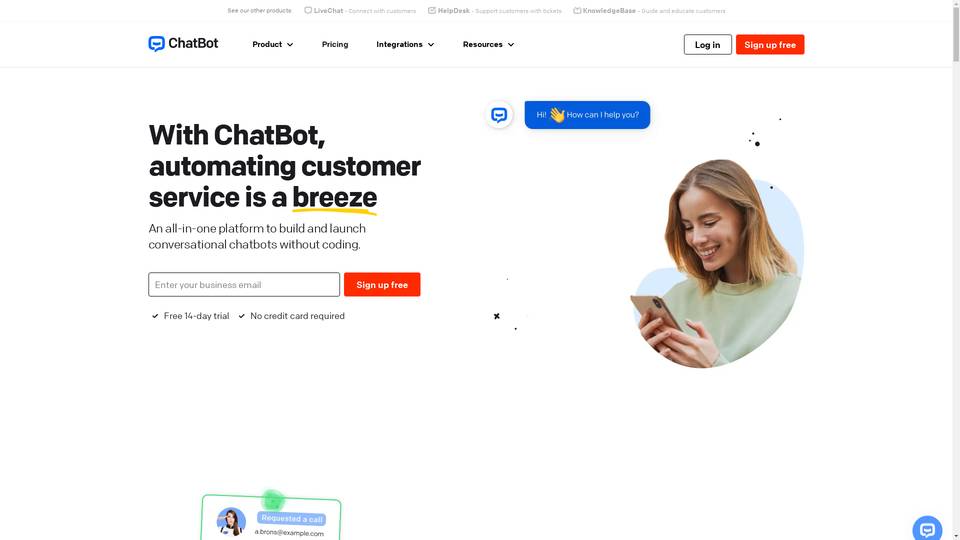
-
An AI-powered chatbot software for automating customer service and improving customer experiences.
-
AI voice generator and research lab with versatile text-to-speech capabilities.
-
AI tool for web/app development, video production & Facebook campaigns

-
A powerful AI tool for scientific text analysis and research optimization.
-
A platform for rapid AI model development and data analysis.