

Details
Description
MiniGPT-4 is an AI tool that enhances vision-language understanding using advanced large language models. By leveraging the power of a frozen visual encoder and a frozen large language model called Vicuna, MiniGPT-4 is capable of generating detailed image descriptions, creating websites from handwritten drafts, and identifying humorous elements within images. Additionally, it can write stories and poems inspired by given images, provide solutions to problems shown in images, and even teach users how to cook based on food photos. The tool achieves high computational efficiency by training only a single linear projection layer to align visual features with the Vicuna model. Its training data consists of approximately five million aligned image-text pairs. The tool"s effectiveness and usability are improved through a two-stage process involving pretraining on raw image-text pairs and fine-tuning with a high-quality, well-aligned dataset using a conversational template. Overall, MiniGPT-4 demonstrates advanced multi-modal generation capabilities and has various potential applications in vision-language understanding.
Link
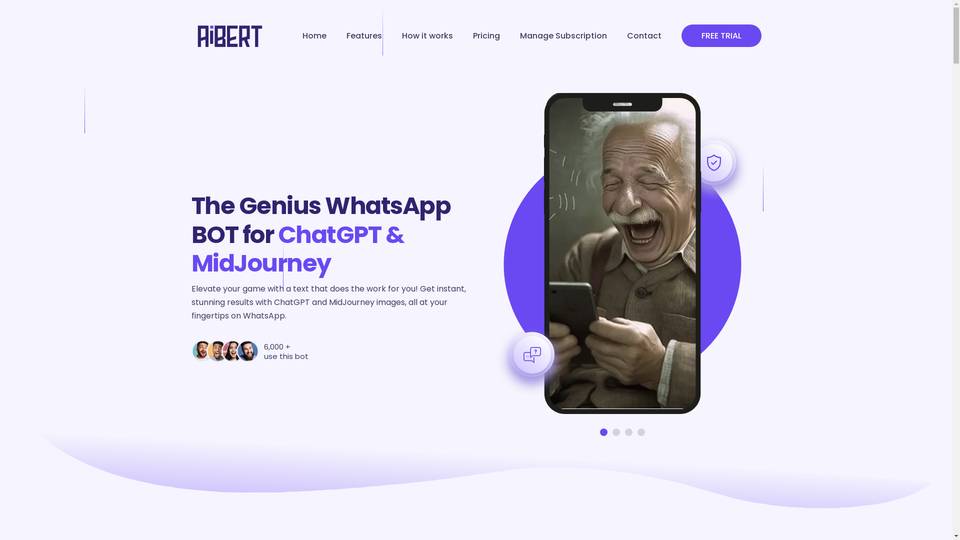
-
An impressive WhatsApp bot that provides instant responses and visually appealing images.
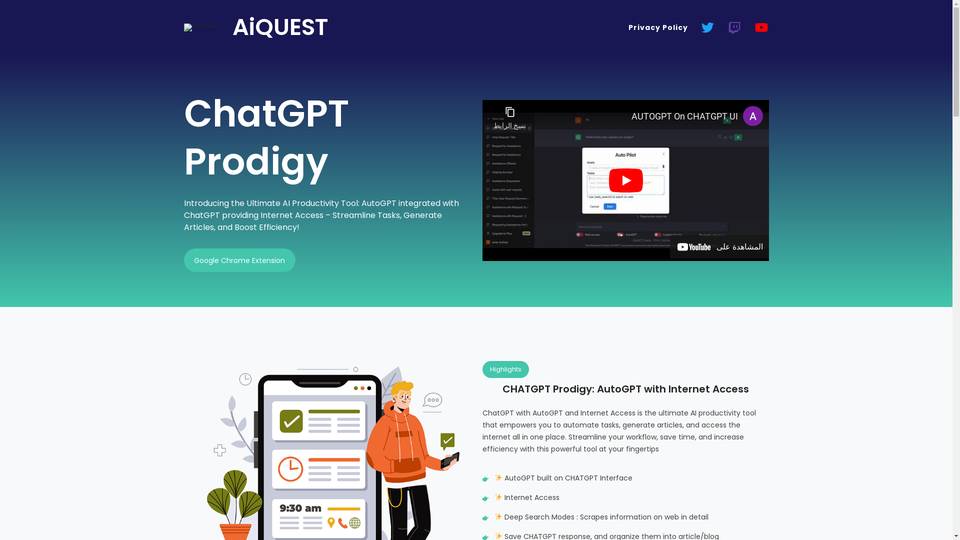
-
ChatGPT Prodigy: AI-powered productivity and research tool with internet access.
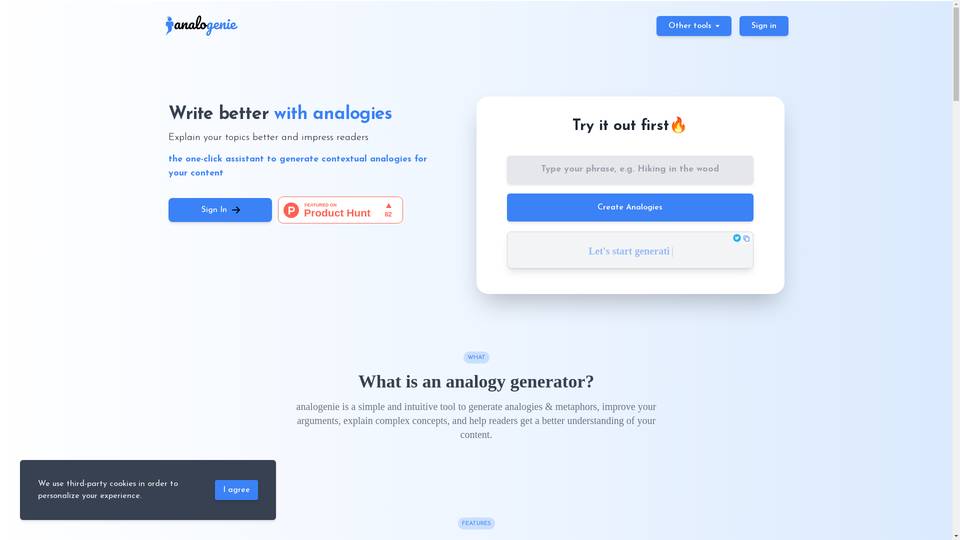
-
AI tool for generating contextual analogies to enhance written content.
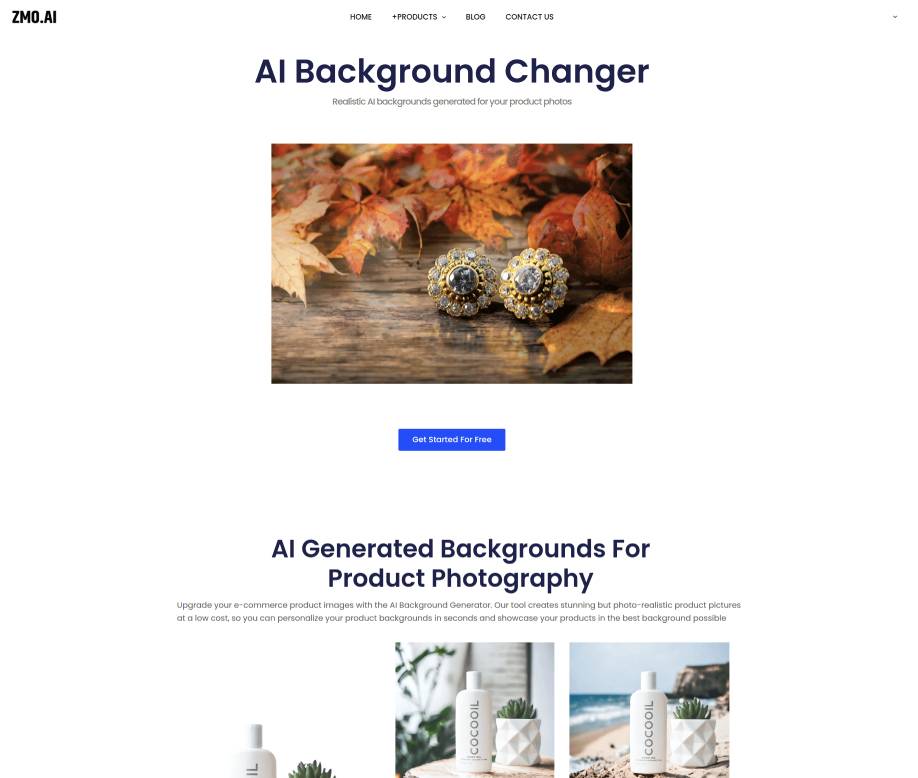
-
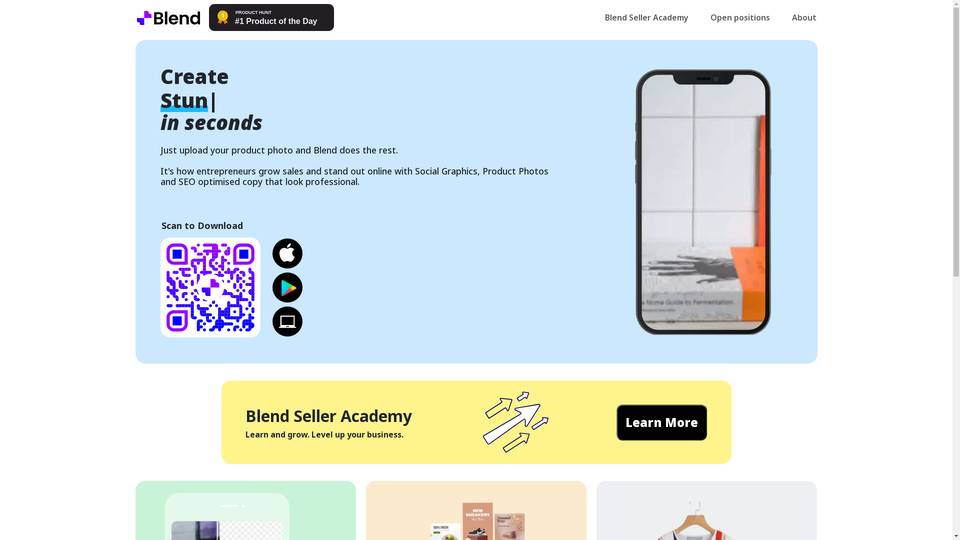
An advanced AI tool for upgrading product images with customizable backgrounds.
-
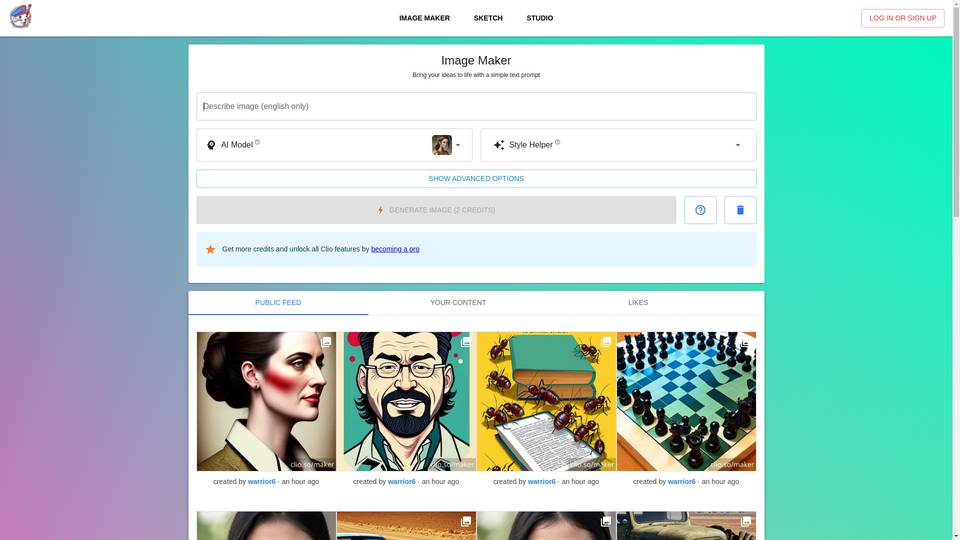
An AI tool for background removal and graphic enhancement.
-
A versatile AI tool for creating unique images.
-
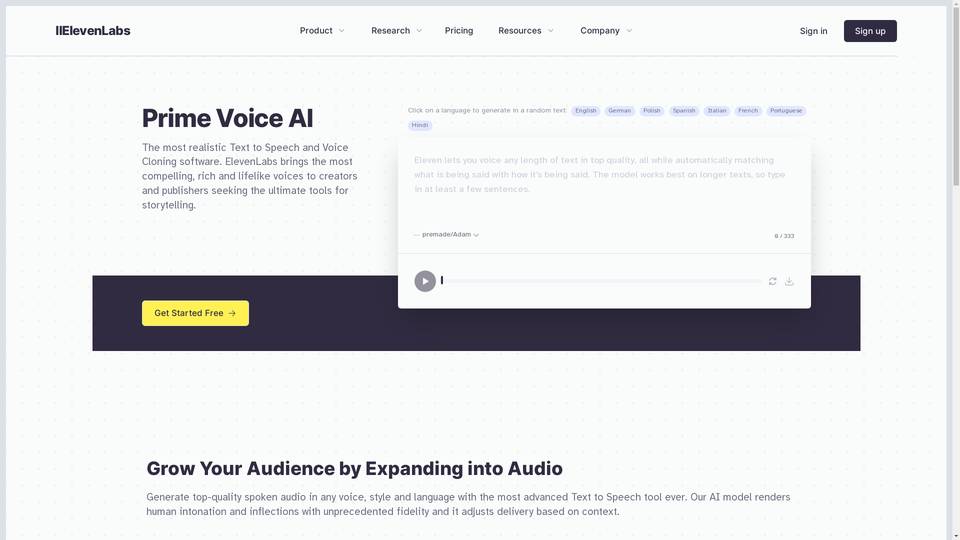
AI voice generator and research lab with versatile text-to-speech capabilities.
-
AI tool for web/app development, video production & Facebook campaigns